miércoles, 20 de noviembre de 2013
ADM ENTRADA Y SALIDA
ADMINISTRACION
DE ENTRADA/SALIDA
CONCEPTOS BASICOS DE E/S
El
sistema de entrada y salida es la parte del S.O. encargada de la administración
de los dispositivos de E/S.
Comprende
tanto la transferencia entre diversos niveles de la memoria como la
comunicación con los periféricos.
Este
sistema proporciona un medio para tratar los archivos y dispositivos de manera
uniforme, actuando como interfaz entre los usuarios y los dispositivos de e/s
que pueden ser manipulados por órdenes de alto nivel.
El SO debe controlar el funcionamiento
de todos los dispositivos de E/S para alcanzar los siguientes objetivos:
DISPOSITIVOS Y MANEJADORES DE DISPOSITIVOS (DEVICE DRIVERS)
DISPOSITIVOS DE E/S
Todos los dispositivos de E/S se
pueden agrupar en tres grandes grupos:
DISPOSITIVOS DE INTERFAZ DE USUARIO
DISPOSITIVOS DE ALMACENAMIENTO
DISPOSITIVOS DE COMUNICACIONES
MANEJADORES DE DISPOSITIVOS (DEVICE DRIVERS)
Las
unidades de E/S tienen una parte mecánica que es el propio dispositivo y otra
electrónica que se llama controlador del dispositivo y actúa como intermediario
entre la computadora y los dispositivos.
Un controlador de dispositivo (llamado
normalmente controlador, o, en inglés, driver) es un programa informático que
permite al sistema operativo interactuar con un periférico.
q
El controlador convierte el flujo de bits en serie
transmitidos desde un dispositivo en un bloque de bytes para la CPU y realizar
las correcciones de los errores que se puedan cometer en la transmisión.
q
El controlador
dispone de tres capas funcionales: La interfaz del bus, el controlador y la
interfaz del dispositivo.
PUERTOS DE E/S
El controlador contiene una serie de
registros llamados puertos de
entrada/salida. Estos registros son accesibles (pueden ser leídos y
modificados) mediante la ejecución de instrucciones máquina. Las operaciones de
E/S se realizan a través de la carga y lectura de estos registros. Casi todo
controlador dispone de los siguientes registros:
q
Registros De Estado
q
Registro De
Ordenes
q
Buffer
REGISTROS DE
ESTADO
Indica la situación actual del
dispositivo (ocupado o desocupado).
REGISTROS DE
ÓRDENES
En este registro se escribe la
operación de E/S que se desea que realice el dispositivo.
BUFFER
Un buffer es un almacén de
información. El buffer del controlador se utiliza para guardar temporalmente
los datos implicados en una operación de E/S.
Los controladores de dispositivo se
suelen agrupar en alguna de las siguientes categorías o clases:
MECANISMOS Y
FUNCIONES DE LOS MANEJADORES DE DISPOSITIVOS (DEVICE DRIVERS)
Los manejadores de dispositivo (device
drivers) se
comunican directamente con los dispositivos o sus controladores o canales.
Los manejadores de dispositivos tienen
la función de comenzar las operaciones de E/S en un dispositivo y procesar la
terminación de una solicitud de E/S.
El sistema de archivos básico trata con bloques de datos que son los
que se intercambian con los discos o cintas. Ubica estos bloques en el
almacenamiento secundario o en el intermedio en memoria principal.
El supervisor básico de E/s se responsabiliza de iniciar y
terminar la E/s con archivos.
Selecciona el dispositivo donde se
realizará la E/S, según el archivo seleccionado. Planifica los accesos a disco
y cinta, asigna los buffers de E/S y reserva la memoria secundaria.
La E/S lógica tiene la función de permitir a los
usuarios y aplicaciones acceder a los registros.
El método de acceso es el nivel más cercano al usuario,
proporcionando una interfaz entre las aplicaciones y los archivos.
ESTRUCTURAS DE
DATOS PARA MANEJO DE DISPOSITIVOS.
Los
procesos de usuario emiten peticiones de entrada/salida al sistema operativo.
Cuando un proceso solicita una operación de E/S, el sistema operativo prepara
dicha operación y bloquea al proceso hasta que se recibe una interrupción del
controlador del dispositivo indicando que la operación está completa.
En el manejo de los dispositivos de
E/S es necesario, introducir dos nuevos términos:
BUFFERING (uso de memoria intermedia).
Trata de mantener ocupados tanto la
CPU como los dispositivos de E/S. Los datos se leen y se almacenan en un
buffer, una vez que los datos se han leído y la CPU va a iniciar inmediatamente
la operación con ellos, el dispositivo de entrada es instruido para iniciar
inmediatamente la siguiente lectura.
La CPU y el dispositivo de entrada
permanecen ocupados. Cuando la CPU esté libre para el siguiente grupo de datos,
el dispositivo de entrada habrá terminado de leerlos. La CPU podrá empezar el
proceso de los últimos datos leídos, mientras el dispositivo de entrada
iniciará la lectura de los datos siguientes.
SPOOLING
Esta forma de procesamiento se
denomina spooling, utiliza el disco como un buffer muy grande para leer tan por
delante como sea posible de los dispositivos de entrada y para almacenar los
ficheros hasta que los dispositivos de salida sean capaces de aceptarlos.
Es una característica utilizada en la
mayoría de los sistemas operativos.
OPERACIONES DE
ENTRADA/SALIDA
Tanto en la E/S programada como la
basada en interrupciones, la CPU debe encargarse de la transferencia de datos
una vez que sabe que hay datos disponibles en el controlador. Una mejora
importante para incrementar la concurrencia entre la CPU y la E/S consiste en
que el controlador del dispositivo se pueda encargar de efectuar la
transferencia de datos. Esta técnica se denomina acceso directo a memoria
(DMA, Direct Memory Access).
ACCESO DIRECTO A MEMORIA (DMA)
Este
dispositivo permite la transferencia directa de información entre la memoria y
los periféricos o viceversa, sin
requerir intervención alguna por parte del procesador.
·
El DMA necesita:
- Registro: almacena
la dirección de memoria desde donde se produce la transferencia.
- Registro contador: guarda
la longitud de bloque a transferir.
- Bits: indica
si la operación es de lectura o escritura.
- Bloque de control: controla
el funcionamiento del sistema.
·
Existen 3 tipos de transferencia para el máximo aprovechamiento del bus:
- Por ráfagas: el DMA
toma el control del bus y no lo suelta hasta terminar la transferencia.
- Por robo de ciclo: el
DMA toma el bus durante un ciclo enviando una palabra cada vez.
- Transparente: se aprovechan los ciclos en que el procesador no usa el bus.
OPERACIONES DE E/S
Existen varias operaciones, las más
importantes son las siguientes:
Lectura
El canal transfiere a memoria
principal un bloque de palabras de tamaño especificado en el campo número de
palabras, en orden ascendente de direcciones, empezando en la dirección
especificada en el campo dirección del dato.
Escritura
El canal transfiere datos de memoria
principal al dispositivo. Las palabras se transfieren en el mismo orden que en
la operación de lectura.
Control
Se utiliza esta orden para enviar
instrucciones específicas al dispositivo de E/S, como rebobinar una cinta
magnética, etc.
Bifurcación
Cumple en el programa de canal la
misma función que una instrucción de salto en un programa normal.

SISTEMAS ARCHIVOS
¿Qué son los sistemas de archivos?
La diferencia entre un disco o partición y el sistema de archivos que contiene es importante. Unos pocos programas (incluyendo, razonablemente, aquellos que crean sistemas de archivos) trabajan directamente en los sectores crudos del disco o partición; si hay un archivo de sistema existente allí será destruido o corrompido severamente. La mayoría de programas trabajan sobre un sistema de archivos, y por lo tanto no utilizarán una partición que no contenga uno (o que contenga uno del tipo equivocado).
Antes de que una partición o disco sea utilizada como un sistema de archivos, necesita ser iniciada, y las estructura de datos necesitan escribirse al disco. Este proceso se denominaconstruir un sistema de archivos.
La mayoría de los sistema de archivos UNIX tienen una estructura general parecida, aunque los detalles exactos pueden variar un poco. Los conceptos centrales son superbloque, nodo-i, bloque de datos, bloque de directorio, y bloque de indirección. El superbloque tiene información del sistema de archivos en conjunto, como su tamaño (la información precisa aquí depende del sistema de archivos). Un nodo-i tiene toda la información de un archivo, salvo su nombre. El nombre se almacena en el directorio, junto con el número de nodo-i. Una entrada de directorio consiste en un nombre de archivo y el número de nodo-i que representa al archivo. El nodo-i contiene los números de varios bloques de datos, que se utilizan para almacenar los datos en el archivo. Sólo hay espacio para unos pocos números de bloques de datos en el nodo-i; en cualquier caso, si se necesitan más, más espacio para punteros a los bloques de datos son colocados de forma dinámica. Estos bloques colocados dinámicamente son bloques indirectos; el nombre indica que para encontrar el bloque de datos, primero hay que encontrar su número en un bloque indirecto.
Los sistemas de archivos UNIX generalmente nos permiten crear un agujero en un archivo (esto se realiza con la llamada al sistema
lseek(); compruebe su página de manual), lo que significa que el sistema de archivos simplemente intenta que en un lugar determinado en el archivo haya justamente cero bytes, pero no existan sectores del disco reservados para ese lugar en el archivo (esto significa que el archivo utilizará un poco menos de espacio en disco). Esto ocurre frecuentemente en especial para pequeños binarios, librerías compartidas de Linux, algunas bases de datos, y algunos pocos casos especiales. (los agujeros se implementan almacenando un valor especial en la dirección del bloque de datos en el bloque indirecto o en el nodo-i. Esta dirección especial indica que ningún bloque de datos está localizado para esa parte del archivo, y por lo tanto, existe un agujero en el archivo).
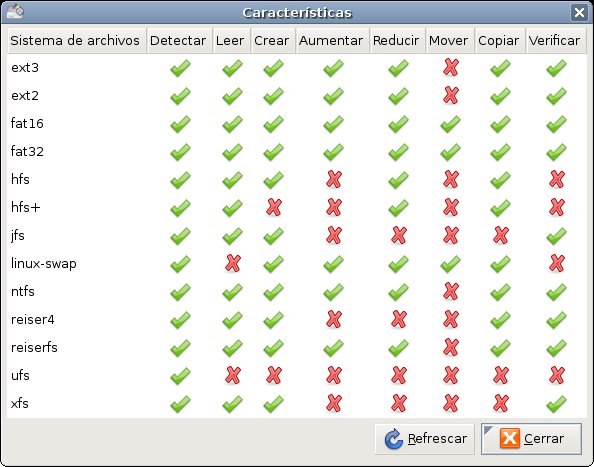
Linux soporta una gran cantidad de tipos diferentes de sistemas de archivos. Para nuestros propósitos los más importantes son:
Adicionalmente, existe soporte para sistemas de archivos adicionales ajenos, para facilitar el intercambio de archivos con otros sistemas operativos. Estos sistemas de archivos ajenos funcionan exactamente como los propios, excepto que pueden carecer de características usuales UNIX , o tienen curiosas limitaciones, u otros inconvenientes.
spacio del disco.
- minix
- El más antiguo y supuestamente el más fiable, pero muy limitado en características (algunas marcas de tiempo se pierden, 30 caracteres de longitud máxima para los nombres de los archivos) y restringido en capacidad (como mucho 64 MB de tamaño por sistema de archivos).
- xia
- Una versión modificada del sistema de archivos minix que eleva los límites de nombres de archivos y tamaño del sistema de archivos, pero por otro lado no introduce características nuevas. No es muy popular, pero se ha verificado que funciona muy bien.
- ext3
- El sistema de archivos ext3 posee todas las propiedades del sistema de archivos ext2. La diferencia es que se ha añadido una bitácora (journaling). Esto mejora el rendimiento y el tiempo de recuperación en el caso de una caída del sistema. Se ha vuelto más popular que el ext2.
- ext2
- El más sistema de archivos nativo Linux que posee la mayor cantidad de características. Está diseñado para ser compatible con diseños futuros, así que las nuevas versiones del código del sistema de archivos no necesitará rehacer los sistemas de archivos existentes.
- ext
- Una versión antigua de ext2 que no es compatible en el futuro. Casi nunca se utiliza en instalaciones nuevas, y la mayoría de la gente que lo utilizaba han migrado sus sistemas de archivos al tipo ext2.
- reiserfs
- Un sistema de archivos más robusto. Se utiliza una bitácora que provoca que la pérdida de datos sea menos frecuente. La bitácora es un mecanismo que lleva un registro por cada transacción que se va a realizar, o que ha sido realizada. Esto permite al sistema de archivos reconstruirse por sí sólo fácilmente tras un daño ocasionado, por ejemplo, por cierres del sistema inadecuados.
Adicionalmente, existe soporte para sistemas de archivos adicionales ajenos, para facilitar el intercambio de archivos con otros sistemas operativos. Estos sistemas de archivos ajenos funcionan exactamente como los propios, excepto que pueden carecer de características usuales UNIX , o tienen curiosas limitaciones, u otros inconvenientes.
- msdos
- Compatibilidad con el sistema de archivos FAT de MS-DOS (y OS/2 y Windows NT).
- umsdos
- Extiende el dispositivo de sistema de archivos msdos en Linux para obtener nombres de archivo largos, propietarios, permisos, enlaces, y archivos de dispositivo. Esto permite que un sistema de archivos msdos normal pueda utilizarse como si fuera de Linux, eliminando por tanto la necesidad de una partición independiente para Linux.
- vfat
- Esta es una extensión del sistema de archivos FAT conocida como FAT32. Soporta tamaños de discos mayores que FAT. La mayoría de discos con MS Windows son vfat.
- iso9660
- El sistema de archivos estándar del CD-ROM; la extensión popular Rock Ridge del estándar del CD-ROM que permite nombres de archivo más largos se soporta de forma automática.
- nfs
- Un sistema de archivos de red que permite compartir un sistema de archivos entre varios ordenadores para permitir fácil acceso a los archivos de todos ellos.
- smbfs
- Un sistema de archivos que permite compartir un sistema de archivos con un ordenador MS Windows. Es compatible con los protocolos para compartir archivos de Windows.
- hpfs
- El sistema de archivos de OS/2.
- sysv
- EL sistema de archivos de Xenix, Coherent y SystemV/386..
spacio del disco.
Existe generalmente poca ventaja en utilizar muchos sistemas de archivos distintos. Actualmente, el más popular sistema de archivos es ext3, debido a que es un sistema de archivos con bitácora. Hoy en día es la opción más inteligente. Reiserfs es otra elección popular porque también posee bitácora. Dependiendo de la sobrecarga del listado de estructuras, velocidad, fiabilidad (percibible), compatibilidad, y otras varias razones, puede ser aconsejable utilizar otro sistema de archivos. Estas necesidades deben decidirse en base a cada caso.
Un sistema de archivos que utiliza bitácora se denomina sistema de archivos con bitácora. Un sistema de archivos con bitácora mantiene un diario, la bitácora, de lo que ha ocurrido en el sistema de archivos. Cuando sobreviene una caída del sistema, o su hijo de dos años pulsa el botón de apagado como el mío adora hacer, un sistema de archivos con bitácora se diseña para utilizar los diarios del sistema de archivos para recuperar datos perdidos o no guardados. Esto reduce la pérdida de datos y se convertirá en una característica estándar en los sistemas de archivos de Linux. De cualquier modo, no extraiga una falsa sensación de seguridad de esto. Como todo en esta vida, puede haber errores. Procure siempre guardar sus datos para prevenir emergencias.
Un sistema de archivos que utiliza bitácora se denomina sistema de archivos con bitácora. Un sistema de archivos con bitácora mantiene un diario, la bitácora, de lo que ha ocurrido en el sistema de archivos. Cuando sobreviene una caída del sistema, o su hijo de dos años pulsa el botón de apagado como el mío adora hacer, un sistema de archivos con bitácora se diseña para utilizar los diarios del sistema de archivos para recuperar datos perdidos o no guardados. Esto reduce la pérdida de datos y se convertirá en una característica estándar en los sistemas de archivos de Linux. De cualquier modo, no extraiga una falsa sensación de seguridad de esto. Como todo en esta vida, puede haber errores. Procure siempre guardar sus datos para prevenir emergencias.
Un sistema de archivos se crea, esto es, se inicia, con el comando mkfs. Existen en realidad programas separados para cada tipo de sistemas de archivos. mkfs es únicamente una careta que ejecuta el programa apropiado dependiendo del tipo de sistemas de archivos deseado. El tipo se selecciona con la opción
Los programas a los que
Para crear un sistema de archivos ext2 en un disquete, se pueden introducir los siguiente comandos:
La opción
El proceso para preparar sistemas de archivos en discos duros o particiones es le mismo que para los disquetes, excepto que no es necesario el formateo.
-t fstype.Los programas a los que
-t fstype llama tienen líneas de comando ligeramente diferentes. Las opciones más comunes e importantes se resumen más abajo; vea las páginas de manual para más información.-t fstype- Selecciona el tipo de sistema de archivos.
-c- Busca bloques defectuosos e inicia la lista de bloques defectuosos en consonancia.
- -l filename
- Lee la lista inicial de bloques defectuosos del archivo dado.
Para crear un sistema de archivos ext2 en un disquete, se pueden introducir los siguiente comandos:
$ fdformat -n /dev/fd0H1440
Double-sided, 80 tracks, 18 sec/track. Total capacity
1440 kB.
Formatting ... done
$ badblocks /dev/fd0H1440 1440 $>$
bad-blocks
$ mkfs -t ext2 -l bad-blocks
/dev/fd0H1440
mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10
360 inodes, 1440 blocks
72 blocks (5.00%) reserved for the super user
First data block=1
Block size=1024 (log=0)
Fragment size=1024 (log=0)
1 block group
8192 blocks per group, 8192 fragments per group
360 inodes per group
Writing inode tables: done
Writing superblocks and filesystem accounting information:
done
$
bad-blocks. Finalmente, se crea el sistema de archivos con la lista de bloques defectuosos iniciada con lo que hubiera encontradobadblocks.La opción
-c podría haberse utilizado con mkfs en lugar de badblocks y un archivo a parte. El ejemplo siguiente hace esto.$ mkfs -t ext2 -c
/dev/fd0H1440
mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10
360 inodes, 1440 blocks
72 blocks (5.00%) reserved for the super user
First data block=1
Block size=1024 (log=0)
Fragment size=1024 (log=0)
1 block group
8192 blocks per group, 8192 fragments per group
360 inodes per group
Checking for bad blocks (read-only test): done
Writing inode tables: done
Writing superblocks and filesystem accounting information:
done
$
-c es más conveniente que la utilización a parte de badblocks, pero badblocks se necesita para comprobar el sistema de archivos una vez creado.El proceso para preparar sistemas de archivos en discos duros o particiones es le mismo que para los disquetes, excepto que no es necesario el formateo.
Antes de que se pueda utilizar un sistema de archivos, debe ser montado. El sistema operativo realiza entonces operaciones de mantenimiento para asegurarse que todo funciona. Como todos los archivos en UNIX están en un mismo árbol de directorios, la operación de montaje provocará que el contenido del nuevo sistema de archivos aparezca como el contenido de un subdirectorio existente en algún sistema de archivos ya montado.
Por ejemplo,
El montaje puede realizarse como en el siguiente ejemplo:
Linux soporta multitud de sistemas de archivos. mount intenta adivinar el tipo de sistema de archivos. Se puede utilizar la
Si no tiene intención de escribir nada en el sistema de archivos, utilice el modificador
El lector atento habrá notado un ligero problema lógico. ¿Cómo se monta el primer sistema de archivos (denominado sistema de archivos raíz, ya que contiene al directorio raíz), si obviamente no puede montarse sobre otro sistema de archivos? Bueno, la respuesta es que se realiza un truco de magia. [14] El sistema de archivos raíz se monta mágicamente a la hora del arranque, y se puede confiar en que siempre será montado. Si el sistema de archivos no puede montarse, el sistema no arrancará. El nombre del sistema de archivos que mágicamente se monta como root está compilado dentro del núcleo, o se especifica utilizando LILO o rdev.
El sistema de archivos raíz se monta generalmente para sólo-lectura. Los guiones (scripts) de inicio ejecutarán entonces fsck para comprobar su validez, y si no hay problemas, volverá a montarlo para permitir la escritura. fsck no debe ejecutarse en sistemas de archivos montados, puesto que cualquier cambio en el sistema de archivos mientras se ejecuta fsck puede causar problemas. Como el sistema de archivos raíz se monta como sólo-lectura mientras se comprueba, fsck puede corregir cualquier problema sin preocuparse, porque la operación de remontaje vaciará cualquier metadato que el sistema de archivos mantuviera en memoria.
En muchos sistemas existen otros sistemas de archivos que también deben montarse de forma automática durante en el arranque. Estos se especifican en el archivo
Cuando un sistema de archivos no se necesita seguir montado, puede desmontarse con umount. umount toma un argumento: o bien el archivo de dispositivo o el punto de montaje. Por ejemplo, para desmontar los directorios del ejemplo anterior, se pueden utilizar los comandos
Lea la página de manual para más información sobre cómo utilizar el comando. Es obligatorio que siempre se desmonte un disquete montado. ¡No saque únicamente el disquete de la disquetera! Debido al cacheado de disco, los datos no se escriben necesariamente hasta que se desmonta el disquete, así que sacar el disquete de la disquetera demasiado pronto puede provocar que el contenido se vuelva erróneo. Si únicamente lee del disquete, esto no es muy usual, pero si escribe, incluso accidentalmente, el resultado puede ser catastrófico.
Montar y desmontar requieren privilegios de superusuario, esto es, sólo root puede hacerlo. La razón para esto es que si un usuario puede montar un disquete en cualquier directorio, entonces es relativamente fácil crear un disquete con, digamos, un caballo de Troya disfrazado de
La última alternativa puede implementarse añadiendo una línea como la siguiente en el archivo
La opción
Si desea otorgar acceso para varios tipos de disquetes, necesita proporcionar distintos puntos de montaje. Las opciones pueden ser diferentes para cada punto de montaje. Por ejemplo, para permitir accesos a disquetes MS-DOS o ext2, se pueden tener las siguientes líneas en
Por ejemplo,
El montaje puede realizarse como en el siguiente ejemplo:
$ mount /dev/hda2 /home
$ mount /dev/hda3 /usr
$
/home y /usr, respectivamente. Se dice que “/dev/hda2 está montado en /home”, e igualmente para /usr. Para ver cualquiera de los sistemas de archivos, se puede mirar el contenido del directorio en el que fue montado, como si fuera cualquier otro directorio. Observe la diferencia entre el archivos de dispositivo, /dev/hda2, y el directorio de montaje, /home. El archivo de dispositivo proporciona acceso al contenido crudo del disco, el directorio de montaje proporciona acceso a los archivos del disco. El directorio de montaje se denomina punto de montaje.Linux soporta multitud de sistemas de archivos. mount intenta adivinar el tipo de sistema de archivos. Se puede utilizar la
-t fstype para especificar el tipo directamente; esto es necesario en determinados casos, puesto que la heurística que utiliza mount no siempre funciona. Por ejemplo, para montar un disquete MS-DOS, se puede utilizar el comando siguiente:$ mount -t msdos /dev/fd0 /floppy
$
/tmp y /var/tmp como sinónimos, y poner /tmp como enlace simbólico a/var/tmp. Cuando el sistema arranca, antes de montar el sistema de archivos /var, se utiliza un directorio /var/tmp residente en el sistema de archivos raíz en su lugar. Cuando /varse monta, convertirá al directorio /var/tmp del sistema de archivos raíz inaccesible. Si /var/tmp no existe en el el sistema de archivos raíz, será imposible utilizar los archivos temporales antes de montar /var.Si no tiene intención de escribir nada en el sistema de archivos, utilice el modificador
-r de mount para realizar un montaje de sólo-lectura. Esto provocará que el núcleo detenga cualquier intento de escribir en el sistema de archivos, y también impedirá que el núcleo actualice el tiempo de acceso a los nodos-i. Montaje de sólo-lectura son necesarios para medios no grabables, como los CD-ROM.El lector atento habrá notado un ligero problema lógico. ¿Cómo se monta el primer sistema de archivos (denominado sistema de archivos raíz, ya que contiene al directorio raíz), si obviamente no puede montarse sobre otro sistema de archivos? Bueno, la respuesta es que se realiza un truco de magia. [14] El sistema de archivos raíz se monta mágicamente a la hora del arranque, y se puede confiar en que siempre será montado. Si el sistema de archivos no puede montarse, el sistema no arrancará. El nombre del sistema de archivos que mágicamente se monta como root está compilado dentro del núcleo, o se especifica utilizando LILO o rdev.
El sistema de archivos raíz se monta generalmente para sólo-lectura. Los guiones (scripts) de inicio ejecutarán entonces fsck para comprobar su validez, y si no hay problemas, volverá a montarlo para permitir la escritura. fsck no debe ejecutarse en sistemas de archivos montados, puesto que cualquier cambio en el sistema de archivos mientras se ejecuta fsck puede causar problemas. Como el sistema de archivos raíz se monta como sólo-lectura mientras se comprueba, fsck puede corregir cualquier problema sin preocuparse, porque la operación de remontaje vaciará cualquier metadato que el sistema de archivos mantuviera en memoria.
En muchos sistemas existen otros sistemas de archivos que también deben montarse de forma automática durante en el arranque. Estos se especifican en el archivo
/etc/fstab ; vea la página de manual de fstab para los detalles en el formato. Los detalles sobre cuándo se montan exactamente los sistemas de archivos adicionales dependen de muchos factores, y pueden ser configurados por cada administrador si lo necesita; vea el Cuando un sistema de archivos no se necesita seguir montado, puede desmontarse con umount. umount toma un argumento: o bien el archivo de dispositivo o el punto de montaje. Por ejemplo, para desmontar los directorios del ejemplo anterior, se pueden utilizar los comandos
$ umount /dev/hda2
$ umount /usr
$
Lea la página de manual para más información sobre cómo utilizar el comando. Es obligatorio que siempre se desmonte un disquete montado. ¡No saque únicamente el disquete de la disquetera! Debido al cacheado de disco, los datos no se escriben necesariamente hasta que se desmonta el disquete, así que sacar el disquete de la disquetera demasiado pronto puede provocar que el contenido se vuelva erróneo. Si únicamente lee del disquete, esto no es muy usual, pero si escribe, incluso accidentalmente, el resultado puede ser catastrófico.
Montar y desmontar requieren privilegios de superusuario, esto es, sólo root puede hacerlo. La razón para esto es que si un usuario puede montar un disquete en cualquier directorio, entonces es relativamente fácil crear un disquete con, digamos, un caballo de Troya disfrazado de
/bin/sh, o cualquier otro programa frecuentemente utilizado. De cualquier modo, se necesita generalmente permitir a los usuarios utilizar los disquetes, y hay varias maneras de hacerlo:- Dar al usuario la contraseña de root. Esto es obviamente inseguro, pero es la solución más sencilla. Funciona muy bien si no hay otras necesidades de seguridad, que es el caso de muchos sistemas personales sin red.
- Utilizar un programa como sudo para permitir a los usuarios que monten. Esto también es inseguro, pero no proporciona privilegios de superusuario directamente a todo el mundo.
- Hacer que el usuario utilice mtools, un paquete para manipular sistemas de archivos MS-DOS, sin tener que montarlos. Esto funciona bien si todo lo que se necesitan son disquetes MS-DOS, pero es bastante lioso en otros casos.
- Listar los dispositivos flexibles y su punto de montaje permitido junto a las opciones oportunas en
/etc/fstab.
/etc/fstab:/dev/fd0 /floppy msdos user,noauto 0 0
Las columnas corresponden a: archivo de dispositivo a montar, directorio de montaje, tipo de sistema de archivos, opciones, frecuencia de copia de seguridad (utilizado por dump), y el número de paso para fsck (especifica el orden en el que los sistemas de archivos son comprobados en el arranque; 0 significa que no se comprueba).La opción
noauto impide que se monte automáticamente al iniciar el sistema (es decir, previene que mount -a la monte). La opción user permite a cualquier usuario montar el sistema de archivos, y, debido a cuestiones de seguridad, deniega la ejecución de programas (normales o con setuid) y la interpretación de sistemas de archivos desde el sistema de archivos montado. Después de eso, cualquier usuario puede montar un disquete con un sistemas de archivos msdos con el comando siguiente:$ mount /floppy
$
Si desea otorgar acceso para varios tipos de disquetes, necesita proporcionar distintos puntos de montaje. Las opciones pueden ser diferentes para cada punto de montaje. Por ejemplo, para permitir accesos a disquetes MS-DOS o ext2, se pueden tener las siguientes líneas en
/etc/fstab:/dev/fd0 /dosfloppy msdos user,noauto 0 0
/dev/fd0 /ext2floppy ext2 user,noauto 0 0
Para sistemas de archivos MS-DOS (no sólo disquetes), probablemente quiera restringir el acceso utilizando las opciones del sistema de archivos uid, gidy umask, descritas en detalle en la página de manual de mount. Si no es cuidadoso, montar un sistema de archivos MS-DOS proporciona al menos acceso de lectura a los archivos que hay en él, lo que no es una buena idea.
Los sistemas de archivos son criaturas complejas, y como tales, tienden a ser propensos a los errores. La corrección y validación de un sistema de archivos puede ser comprobada utilizando el comando fsck. Puede ser instruido para reparar cualquier problema menor que encuentre, y alertar al usuario si hay errores irreparables. Afortunadamente, el código implementado en los sistemas de archivos puede estudiarse de forma muy efectiva, así que escasamente hay problemas, y normalmente son causados por fallos de alimentación, hardware defectuoso, o errores de operación; por ejemplo, no apagar el sistema adecuadamente.
La mayoría de los sistemas se configuran para ejecutar fsck automáticamente durante el arranque, así que cualquier error se detecta (y esperemos que corregido) antes que el sistema se utilice. Utilizar un sistema de archivos corrupto tiende a empeorar las cosas: si las estructuras de datos se mezclan, utilizar el sistema de archivos probablemente las mezclará aún más, resultando en una mayor pérdida de datos. En cualquier caso, fsck puede tardar un tiempo en ejecutarse en sistemas de archivos grandes, y puesto que los errores casi nunca suceden si el sistema se ha apagado adecuadamente, pueden utilizarse un par de trucos para evitar realizar comprobaciones en esos casos. El primero es que si existe el archivo
La comprobación automática sólo funciona para los sistemas de archivos que se montan automáticamente en el arranque. Utilice fsck de forma manual para comprobar otros sistemas de archivos, por ejemplo, disquetes.
Si fsck encuentra problemas irreparables, necesita conocimientos profundos de cómo funciona en general un sistema de archivos, y en particular el tipo del sistema de archivos corrupto, o buenas copias de seguridad. Lo último es fácil (aunque algunas veces tedioso) de arreglar, el precedente puede solucionarse a través de un amigo, los grupos de noticias y listas de correo de Linux, o alguna otra fuente de soporte, si no sabe cómo hacerlo usted mismo. Me gustaría contarle más sobre el tema, pero mi falta de formación y experiencia en este asunto me lo impiden. El programa de Theodore Ts'o debugfs puede ser de ayuda.
fsck debe ser utilizado únicamente en sistemas de archivos desmontados, nunca en sistemas de archivos montados (a excepción del raíz en sólo-lectura en el arranque). Esto es así porque accede al disco directamente, y puede por lo tanto modificar el sistema de archivos sin que el sistema operativo se percate de ello. Habrá problemas, si el sistema operativo se confunde.
La mayoría de los sistemas se configuran para ejecutar fsck automáticamente durante el arranque, así que cualquier error se detecta (y esperemos que corregido) antes que el sistema se utilice. Utilizar un sistema de archivos corrupto tiende a empeorar las cosas: si las estructuras de datos se mezclan, utilizar el sistema de archivos probablemente las mezclará aún más, resultando en una mayor pérdida de datos. En cualquier caso, fsck puede tardar un tiempo en ejecutarse en sistemas de archivos grandes, y puesto que los errores casi nunca suceden si el sistema se ha apagado adecuadamente, pueden utilizarse un par de trucos para evitar realizar comprobaciones en esos casos. El primero es que si existe el archivo
/etc/fastboot, no se realizan comprobaciones. El segundo es que el sistema de archivos ext2 tiene una marca especial en su superbloque que indica si el sistema de archivos se desmontó adecuadamente después del montaje previo. Esto permite a e2fsck (la versión de fsck para el sistema de archivos ext2) evitar la comprobación del sistema de archivos si la bandera indica que se realizó el desmontaje (la suposición es que un desmontaje adecuado indica que no hay problemas). Que el truco de /etc/fastboot funcione en su sistema depende de sus guiones (scripts) de inicio, pero el truco de ext2 funciona cada vez que utilice e2fsck. Debe ser sobrepasado explícitamente con una opción de e2fsck para ser evitado. (Vea la página de manual de e2fsck para los detalles sobre cómo.).La comprobación automática sólo funciona para los sistemas de archivos que se montan automáticamente en el arranque. Utilice fsck de forma manual para comprobar otros sistemas de archivos, por ejemplo, disquetes.
Si fsck encuentra problemas irreparables, necesita conocimientos profundos de cómo funciona en general un sistema de archivos, y en particular el tipo del sistema de archivos corrupto, o buenas copias de seguridad. Lo último es fácil (aunque algunas veces tedioso) de arreglar, el precedente puede solucionarse a través de un amigo, los grupos de noticias y listas de correo de Linux, o alguna otra fuente de soporte, si no sabe cómo hacerlo usted mismo. Me gustaría contarle más sobre el tema, pero mi falta de formación y experiencia en este asunto me lo impiden. El programa de Theodore Ts'o debugfs puede ser de ayuda.
fsck debe ser utilizado únicamente en sistemas de archivos desmontados, nunca en sistemas de archivos montados (a excepción del raíz en sólo-lectura en el arranque). Esto es así porque accede al disco directamente, y puede por lo tanto modificar el sistema de archivos sin que el sistema operativo se percate de ello. Habrá problemas, si el sistema operativo se confunde.
Puede ser buena idea comprobar los bloques defectuosos periódicamente. Esto se realiza con el comando badblocks. Saca una lista de los números de todos los bloques malos que puede encontrar. Esta lista puede introducirse en fsck para grabar en el sistema de archivos las estructuras de datos para que el sistema operativo no intente utilizar los bloques malos para almacenar datos. El ejemplo siguiente muestra cómo puede hacerse esto.
$ badblocks /dev/fd0H1440 1440 >
bad-blocks
$ fsck -t ext2 -l bad-blocks
/dev/fd0H1440
Parallelizing fsck version 0.5a (5-Apr-94)
e2fsck 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Check reference counts.
Pass 5: Checking group summary information.
/dev/fd0H1440: ***** FILE SYSTEM WAS MODIFIED *****
/dev/fd0H1440: 11/360 files, 63/1440 blocks
$
Cuando un archivo se escribe en el disco, no puede escribirse siempre en bloques consecutivos. Un archivos que no está almacenado en bloques consecutivos está fragmentado. Leer un archivo fragmentado requiere mayor tiempo, puesto que la cabeza de lectura-escritura del disco debe moverse más. Es deseable evitar la fragmentación, aunque es un problema menor en un sistema con un buen caché buffer con lectura progresiva.
El sistema de archivos ext2 intenta mantener la fragmentación al mínimo, manteniendo todos los bloques de un archivo juntos, incluso cuando no pueden almacenarse en sectores consecutivos. Ext2 efectivamente localiza el bloque libre más cercano a los otros bloques del archivo. Por lo tanto para ext2 hay poca necesidad de preocuparse por la fragmentación. Existe un programa para desfragmentar un sistema de archivos ext2, llamado extrañamente defrag
Existen muchos programas de desfragmentación MS-DOS que mueven los bloques por todo el sistema de archivos para eliminar la fragmentación. Para otros sistemas de archivos, la desfragmentación debe hacerse guardando el sistema de archivos, volverlo a crear, y restaurando los archivos de la copia guardada. Guardar un sistema de archivos antes de desfragmentarlo es una buena idea para cualquier sistema de archivos, puesto que muchas cosas pueden ir mal durante la desfragmentación.
El sistema de archivos ext2 intenta mantener la fragmentación al mínimo, manteniendo todos los bloques de un archivo juntos, incluso cuando no pueden almacenarse en sectores consecutivos. Ext2 efectivamente localiza el bloque libre más cercano a los otros bloques del archivo. Por lo tanto para ext2 hay poca necesidad de preocuparse por la fragmentación. Existe un programa para desfragmentar un sistema de archivos ext2, llamado extrañamente defrag
Existen muchos programas de desfragmentación MS-DOS que mueven los bloques por todo el sistema de archivos para eliminar la fragmentación. Para otros sistemas de archivos, la desfragmentación debe hacerse guardando el sistema de archivos, volverlo a crear, y restaurando los archivos de la copia guardada. Guardar un sistema de archivos antes de desfragmentarlo es una buena idea para cualquier sistema de archivos, puesto que muchas cosas pueden ir mal durante la desfragmentación.
Algunas herramientas adicionales pueden resultar útiles para manejar sistemas de archivos. df muestra el espacio libre en disco de uno o más sistemas de archivos. du muestra cuánto espacio en disco ocupa un directorio y los archivos que contiene. Estos pueden utilizarse para encontrar desperdiciadores de espacio en disco. Ambos tienen páginas de manual que detallan las (muchas) opciones que pueden utilizarse.
sync fuerza que todos los bloques en el buffer caché no escritos (vea la Sección 7.6“ El Buffer Cache”) se escriban al disco. Es raro hacer esto esto a mano; el demonio update hace esto automáticamente. Puede ser útil en caso de catástrofe, por ejemplo si update o su proceso ayudante bdflush muere, o si debe apagar el ordenador ahora y no puede esperar que se ejecute update. De nuevo, están las páginas de manual. El comando man es su mejor amigo en linux. Su sobrino apropos es también muy útil cuando no sabe cuál es el nombre del comando que quiere.
sync fuerza que todos los bloques en el buffer caché no escritos (vea la Sección 7.6“ El Buffer Cache”) se escriban al disco. Es raro hacer esto esto a mano; el demonio update hace esto automáticamente. Puede ser útil en caso de catástrofe, por ejemplo si update o su proceso ayudante bdflush muere, o si debe apagar el ordenador ahora y no puede esperar que se ejecute update. De nuevo, están las páginas de manual. El comando man es su mejor amigo en linux. Su sobrino apropos es también muy útil cuando no sabe cuál es el nombre del comando que quiere.
Además del creador (mke2fs) y del comprobador (e2fsck) de sistemas de archivos accesibles directamente o a través de las caretas independientes del tipo del sistema de archivos, ext2 posee herramientas adicionales que pueden resultar útiles.
tune2fs ajusta parámetros del sistema de archivos. Algunos de los parámetros más interesantes son:
tune2fs ajusta parámetros del sistema de archivos. Algunos de los parámetros más interesantes son:
- Un contador máximo de montados. e2fsck fuerza una comprobación cuando el sistema de archivos se ha montado demasiadas veces, incluso si la bandera de limpiado está activa. Para un sistema que se utiliza para desarrollo o pruebas de sistema, puede ser una buena idea reducir este límite.
- Un tiempo máximo entre comprobaciones. e2fsck puede también forzar un tiempo máximo entre dos comprobaciones, incluso si la bandera de limpiado está activa, y el sistema de archivos no se monta frecuentemente. De cualquier forma, esto puede desactivarse.
- Número de bloques reservados para root. Ext2 reserva algunos bloques para root de manera que si el sistema de archivos se llena, todavía será posible realizar tareas de administración sin tener que borrar nada. La cantidad reservada es por defecto el 5%, lo que en la mayoría de discos no supone un desperdicio. De cualquier manera, para los disquetes no existe justificación en reservar ningún bloque
MEMORIA VIRTUAL DEL SISTEMA OPERATIVO
ESTRUCTURAS DE HARDWARE Y DE CONTROL
Los métodos de administración de la memoria principal, que no utilizan Memoria Virtual y esquemas de Paginación y Segmentación, es decir que llevan a las direcciones directamente al bus de la memoria, tienen un inconveniente: producen lo que se denomina fragmentación.
La fragmentación, que son huecos en la memoria que no pueden usarse debido a lo pequeño de su espacio, provoca un desperdicio de memoria principal.
Una posible solución para la fragmentación externa es permitir que espacio de direcciones lógicas lleve a cabo un proceso en direcciones no contiguas, así permitiendo al proceso ubicarse en cualquier espacio de memoria física que esté disponible, aunque esté dividida. Una forma de implementar esta solución es a través del uso de un esquema de paginación. La paginación evita el considerable problema de ajustar los pedazos de memoria de tamaños variables que han sufrido los esquemas de manejo de memoria anteriores. Dado a sus ventajas sobre los métodos previos, la paginación, en sus diversas formas, es usada en muchos sistemas operativos.
Al utilizar la memoria virtual, las direcciones no pasan en forma directa al bus de memoria, sino que van a una unidad administradora de la memoria (MMU –Memory Management Unit). Estas direcciones generadas por los programas se llaman direcciones virtuales y conforman el hueco de direcciones virtuales. Este hueco se divide en unidades llamadas páginas. Las unidades correspondientes en la memoria física se llaman marcos para página o frames. Las páginas y los marcos tienen siempre el mismo tamaño.
Comparando la paginación y segmentación simple por un lado, con la partición estática y dinámica por el otro, se establecen las bases para un avance fundamental en la gestión de memoria, y es que:
· Se puede cargar y descargar un proceso de la memoria principal de tal forma que ocupe regiones diferentes de la memoria principal en momentos distintos a lo largo de su ejecución.
· Un proceso puede dividirse en varias partes (páginas o segmentos) y no es necesario que estas partes se encuentren contiguas en la memoria principal.
Si estas dos características están presentes, no será necesario que todas las páginas o todos los segmentos de un proceso estén en la memoria durante la ejecución.
El término fragmento hace referencia tanto a páginas como a segmentos, dependiendo de si se emplea paginación o segmentación. Supóngase que se trae un proceso a la memoria en un momento dado, el S.O comienza trayendo sólo unos pocos fragmentos, incluido el fragmento que contiene el comienzo del programa.
Se llamará conjunto residente del proceso a la parte que está realmente en la memoria principal.
Si el procesador encuentra una dirección lógica que no está en la memoria principal, genera una interrupción que indica un fallo de acceso a la memoria. El S.O pone al proceso interrumpido en estado Bloqueado y toma el control. Para que la ejecución de este proceso siga más tarde, el S.O necesita traer a la memoria principal el fragmento del proceso que contiene la dirección. Para ello se emite una solicitud de Lectura de E/S al disco; luego se expide otro proceso para que se ejecute mientras se realiza la operación.
Una vez que el fragmento deseado se ha traído a la memoria principal y se ha emitido la interrupción de E/S, se devuelve el control al S.O, que coloca el proceso afectado en el estado de Listo.
MEMORIA VIRTUAL
La memoria virtual es una técnica para proporcionar la simulación de un espacio de memoria mucho mayor que la memoria física de una máquina. Esta "ilusión" permite que los programas se hagan sin tener en cuenta el tamaño exacto de la memoria física.
La ilusión de la memoria virtual está soportada por el mecanismo de traducción de memoria, junto con una gran cantidad de almacenamiento rápido en disco duro. Así en cualquier momento el espacio de direcciones virtual hace un seguimiento de tal forma que una pequeña parte de él, está en memoria real y el resto almacenado en el disco, y puede ser referenciado fácilmente.
Debido a que sólo la parte de memoria virtual que está almacenada en la memoria principal, es accesible a la CPU, según un programa va ejecutándose, la proximidad de referencias a memoria cambia, necesitando que algunas partes de la memoria virtual se traigan a la memoria principal desde el disco, mientras que otras ya ejecutadas, se pueden volver a depositar en el disco (archivos de paginación).
La memoria virtual ha llegado a ser un componente esencial de la mayoría de los S.O actuales. Y como en un instante dado, en la memoria sólo se tienen unos pocos fragmentos de un proceso dado, se pueden mantener más procesos en la memoria. Es más, se ahorra tiempo, porque los fragmentos que no se usan no se cargan ni se descargan de la memoria. Sin embargo, el S.O debe saber cómo gestionar este esquema.
La memoria virtual también simplifica la carga del programa para su ejecución llamado reubicación, este procedimiento permite que el mismo programa se ejecute en cualquier posición de la memoria física.
En un estado estable, prácticamente toda la memoria principal estará ocupada con fragmentos de procesos, por lo que el procesador y el S.O tendrán acceso directo a la mayor cantidad de procesos posibles, y cuando el S.O traiga a la memoria un fragmento, deberá expulsar otro. Si expulsa un fragmento justo antes de ser usado, tendrá que traer de nuevo el fragmento de manera casi inmediata. Demasiados intercambios de fragmentos conducen a lo que se conoce como hiperpaginación: donde el procesador consume más tiempo intercambiando fragmentos que ejecutando instrucciones de usuario. Para evitarlo el S.O intenta adivinar, en función de la historia reciente, qué fragmentos se usarán con menor probabilidad en un futuro próximo.
Los argumentos anteriores se basan en el principio de cercanía o principio de localidad que afirma que las referencias a los datos y el programa dentro de un proceso tienden a agruparse. Por lo tanto, es válida la suposición de que, durante cortos períodos de tiempo, se necesitarán sólo unos pocos fragmentos de un proceso.
Una manera de confirmar el principio de cercanía es considerar el rendimiento de un proceso en un entorno de memoria virtual.
El principio de cercanía sugiere que los esquemas de memoria virtual pueden funcionar. Para que la memoria virtual sea práctica y efectiva, se necesitan dos ingredientes. Primero, tiene que existir un soporte de hardware y, en segundo lugar, el S.O debe incluir un software para gestionar el movimiento de páginas o segmentos entre memoria secundaria y memoria principal.
Justo después de obtener la dirección física y antes de consultar el dato en memoria principal se busca en memoria-cache, si esta entre los datos recientemente usados la búsqueda tendrá éxito, pero si falla, la memoria virtual consulta memoria principal , ó, en el peor de los casos se consulta de disco (swapping).
Memoria Virtual = Memoria Física + Area de Swapping en Disco
PAGINACION
El término memoria virtual se asocia normalmente con sistemas que emplean paginación, aunque también se puede usar memoria virtual basada en la segmentación. El uso de la paginación en la memoria virtual fue presentado por primera vez en el computador Atlas.
Cada proceso tiene su propia tabla de páginas y cuando carga todas sus páginas en la memoria principal, se crea y carga en la memoria principal una tabla de páginas. Cada entrada de la tabla de páginas contiene el número de marco de la página correspondiente en la memoria principal. Puesto que sólo algunas de las páginas de un proceso pueden estar en la memoria principal, se necesita un bit en cada entrada de la tabla para indicar si la página correspondiente está presente (P) en la memoria principal o no. Si el bit indica que la página está en la memoria, la entrada incluye también el número de marco para esa página.
Otro bit de control necesario en la entrada de la tabla de páginas es el bit de modificación (M), para indicar si el contenido de la página correspondiente se ha alterado desde que la página se cargó en la memoria principal. Si no ha habido cambios, no es necesario escribir la página cuando sea sustituida en el marco que ocupa actualmente.
Estructura de la tabla de páginas
El mecanismo básico de lectura de una palabra de la memoria supone la traducción por medio de la tabla de páginas de una dirección virtual o lógica, formada por un número de página y un desplazamiento, a una dirección física que está formada por un número de marco y un desplazamiento.
Con la memoria virtual, la CPU produce direcciones virtuales que son traducidas por una combinación de hardware y software a direcciones físicas, pues pueden ser utilizadas para acceder a memoria principal. Este proceso se denomina correspondencia de memoria o traducción de direcciones. Actualmente los dos niveles de la jerarquía de memoria controlados por la memoria virtual son las DRAM y los Discos magnéticos.
Puesto que la tabla de páginas es de longitud variable, en función del tamaño del proceso, no es posible suponer que quepa en los registros.
 |
Suscribirse a:
Comentarios (Atom)